So, the actual problem with ABR is that it is an undocumented binary format. Binary formats, unlike XML (which Krita uses 90% of the time), or stuff like JSON, is a file filled with nothing but values, and you have to manually figure out which values belong with which bit of data. For example, this is how a vector mask looks like in PSD:
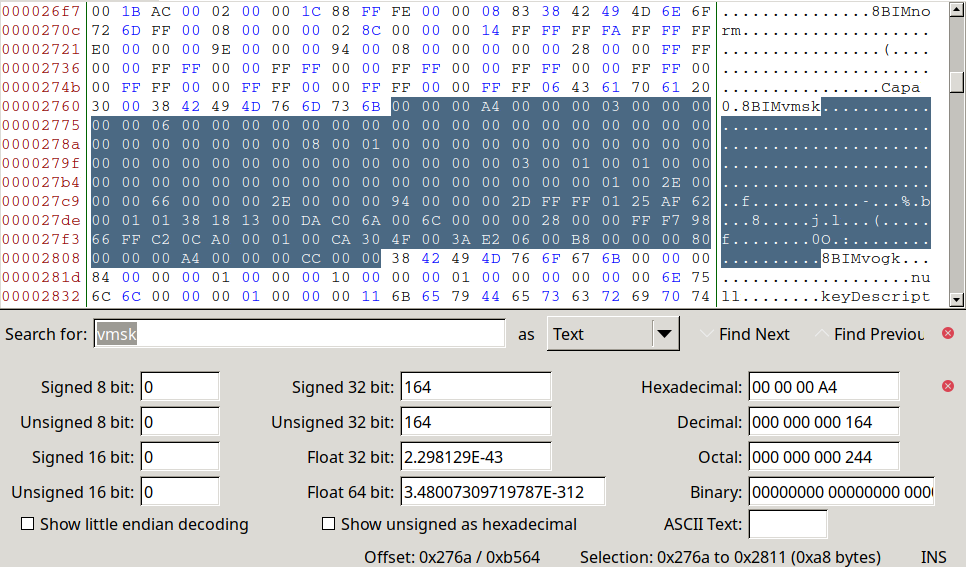
When we program in support for a feature in a binary format like PSD, we need to look at the existing documentation to start with, then we also need a whole bunch of test files to check against, because the PSD documentation is filled with flaws and errors.
With an undocumented binary format, like ABR, it gets even harder, because you then need to reverse engineer it. This involves comparing a whole lot of files, and then sorta seeing where they differ and trying to guess from the patterns whether you are looking at a color, or a curve or a toggle. For example, all PSD blocks end with 8BIM (which is either 34 42 49 4D or 4D 49 42 34 depending on the computer it was saved with), so maybe something like ABR has the same thing going on. This is probably what the artstudio pro developers did.
Furthermore, after figuring out which value is what, you also need to figure out how exactly all the little numbers create a brush preset. Maybe the numbers are stored in percentages, or maybe the size is actually in ‘radius’ instead of ‘diameter’, so that too needs a ton of test files.
Here’s some very clear examples of reversed-engineered palette formats. For ASE for example, my code would look something like this:
QBuffer buf(&data);
buf.open(QBuffer::ReadOnly);
QByteArray signature;
signature = buf.read(4);
if (signature != "ASEF") {
return false;
}
Where I load the first 4 bytes (that’s the little blocks of numbers on the left), and check if I can read them as text, and whether the text spells out “ASEF”, if not, I have to break off loading, because the file is incorrect.
Developers are usually a bit hesitant to support binary file formats that haven’t got a proper standard or documentation (for example, most image formats are binary, but PNG and JPEG have standards documents that has been assembled and reviewed by a ton of programmers and has example code), because it can take a ton of work to get the data out, saving is even scarier: If you make a mistake with the order of the bytes, you end up with a corrupted file that cannot be reopened anymore.
(This is also why hard drive failures corrupt files, the hard drive starts making mistakes as its components deteriorate, jumbling up the bytes when it’s writing or reading files)
Because time is scarce, there’s a good chance a dev might rather want to spend it on something else, like adding a new feature, speed improvements, or fixing bugs. I hope this helps getting an idea of the kind of challenges we face when dealing with binary formats.