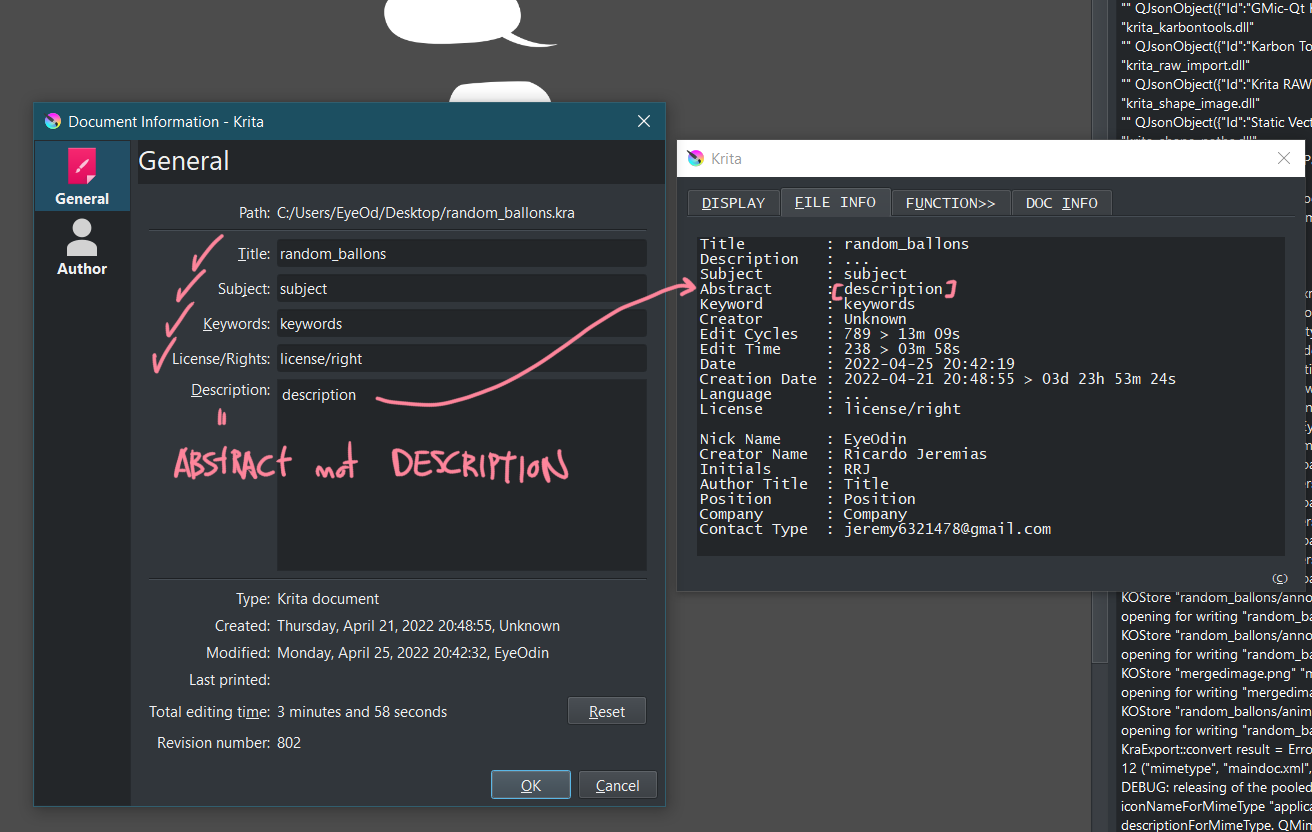
what I used as reference to create my read was this section:
documentInfo() -> str
@brief documentInfo creates and XML document representing document and author information.
@return a string containing a valid XML document with the right information about the document and author. The DTD can be found here: https://phabricator.kde.org/source/krita/browse/master/krita/dtd/
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE document-info PUBLIC '-//KDE//DTD document-info 1.1//EN' 'http://www.calligra.org/DTD/document-info-1.1.dtd'>
<document-info xmlns="http://www.calligra.org/DTD/document-info">
<about>
<title>My Document</title>
<description></description>
<subject></subject>
<abstract><![CDATA[]]></abstract>
<keyword></keyword>
<initial-creator>Unknown</initial-creator>
<editing-cycles>1</editing-cycles>
<editing-time>35</editing-time>
<date>2017-02-27T20:15:09</date>
<creation-date>2017-02-27T20:14:33</creation-date>
<language></language>
</about>
<author>
<full-name>Boudewijn Rempt</full-name>
<initial></initial>
<author-title></author-title>
<email></email>
<telephone></telephone>
<telephone-work></telephone-work>
<fax></fax>
<country></country>
<postal-code></postal-code>
<city></city>
<street></street>
<position></position>
<company></company>
</author>
</document-info>
however when you write in krita’s document information, the description line fill the abstract line.
for you to test on your KRA files, open the file and then run this section of code on scripter to check if abstract and description are not mixed.
import krita
import xml
ki = Krita.instance()
ad = ki.activeDocument()
text = ad.documentInfo()
ET = xml.etree.ElementTree
root = ET.fromstring(text)
title = root[0][0].text # title
description = root[0][1].text # description
subject = root[0][2].text # subject
abstract = root[0][3].text # abstract
keyword = root[0][4].text # keyword
initial_creator = root[0][5].text # initial-creator
editing_cycles = root[0][6].text # editing-cycles
editing_time = root[0][7].text # editing-time
date = root[0][8].text # date
creation_date = root[0][9].text # creation-date
language = root[0][10].text # language
license = root[0][11].text # license
nick_name = root[1][0].text # full-name
creator_first_name = root[1][1].text # creator-first-name
creator_last_name = root[1][2].text # creator-last-name
initial = root[1][3].text # initial
author_title = root[1][4].text # author-title
position = root[1][5].text # position
company = root[1][6].text # company
contact_type = root[1][7].text # contact type
print("description = " + str(description))
print("abstract = " + str(abstract))
XML doesn’t really have any “order”, everything on the same level are equal. So you shouldn’t be extracting it linearly unless it doesn’t matter. Not to mention there is no guarantee new elements won’t be added to the document.
Unload them into a dict instead:
import krita
import xml
ki = Krita.instance()
ad = ki.activeDocument()
text = ad.documentInfo()
ET = xml.etree.ElementTree
root = ET.fromstring(text)
meta = {}
for rel in root:
for el in rel:
prefix, tagName = el.tag.split('}')
meta[tagName if prefix else prefix] = el.text
print ( meta )
If you really need them as top level variables, then put them in globals() or locals()
I see this will not be something to be corrected with just krita itself as it seems a wider bug.
I have so many questions that will never be answered now, I will just treat abstract as the description then and hope they never fix that bug I guess.
Beyond this the tag “Contact” can appear repeated several times so making a dictionary kills all instances when it is repeated. like you have contact for fax, contact for telephone post address and so and so on.
import krita
import xml
ki = Krita.instance()
ad = ki.activeDocument()
text = ad.documentInfo()
ET = xml.etree.ElementTree
root = ET.fromstring(text)
meta = { 'contact':[] }
for rel in root:
for el in rel:
prefix, tagName = el.tag.split('}')
tagName = tagName if prefix else prefix
if tagName == 'contact':
meta[tagName].append([el.attrib['type'],el.text])
else:
meta[tagName] = el.text
print ( meta )
So I ended up doing something like this for the UI.
I built a separate list for contacts and do a separate for loop to add items to the widget list.
all seems to be working it even dettects the name difference between the original name and the path name.
now I was set out to do a setDocumentInfo(string) but I am still not sure of the input string but I imagine I just have to mimic the same string I get when I documentInfo() .
I updated imagine board and just swapped the abstract and description tag when loading up as you can see here. I really hope they maintain this off disposition because I donno if I will be able to detect right away if they change it by chance.
Do a check on the namespace, if the namespace doesn’t change you know everything is correct. Or since it is in the header with the version you can do if 'http://www.calligra.org/DTD/document-info-1.1.dtd' in text:
And if not, put a warning.
Or if you think description will end up being used instead of abstract, just check if description is empty and if not use abstract. Since description is unused anyways.
Well I donno if I would do that last detection because if all works good I could give use to both. How useful it is, is debatable.
I was exposing all entries just not give edit options to all like resetting the clocks. I don’t know why I think resetting the clocks to be such a dirty trick let alone edit the values to what you want as I could have given. Changing author information also sounded bad so I ended up with something very similar to document information. But I do wonder.
What I am pondering is to alter a bit how to use the keywords. Because how imagine board works.